We present DepthFM, a method that advances monocular depth estimation by framing it as direct transport between paired image and depth distributions. We find that flow matching effectively addresses this, as its straight trajectories through solution space provide efficiency and high quality. On the other hand, depth estimation has long faced challenges in training and data efficiency due to optimization difficulties and data annotation. To address this, we incorporate external knowledge from pretrained foundation diffusion models and discriminative depth estimators. On standard benchmarks of complex natural scenes, our approach achieves competitive performance by improving sampling, training, and data efficiency, despite being trained on minimal synthetic data.
The gallery below presents images sourced from the internet, accompanied by a comparison between our DepthFM, ZoeDepth, and Marigold. Utilize the slider and gestures to reveal details on both sides. Note that our depth maps in the first two rows are generated with 10 inference steps, while the last row showcases our results with one single inference step compared to Marigold with two inference steps. We achieve significantly faster inference speed compared to diffusion-based baselines, while maintaining high quality.























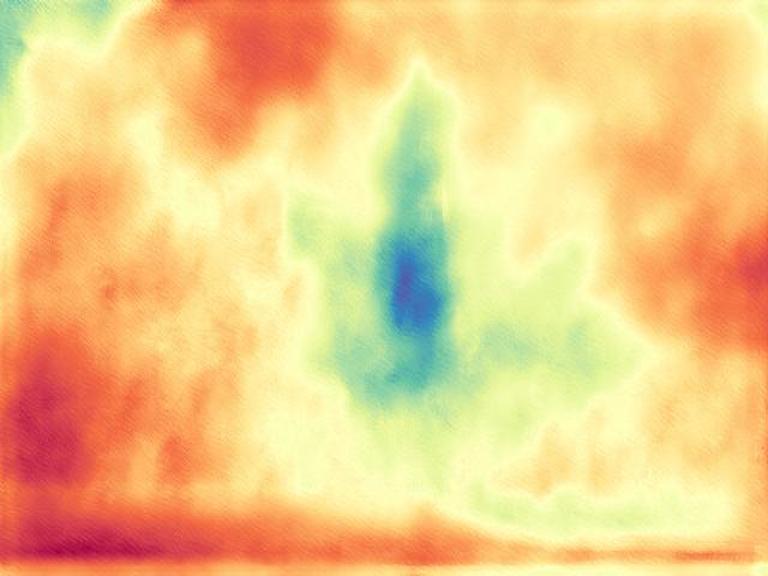








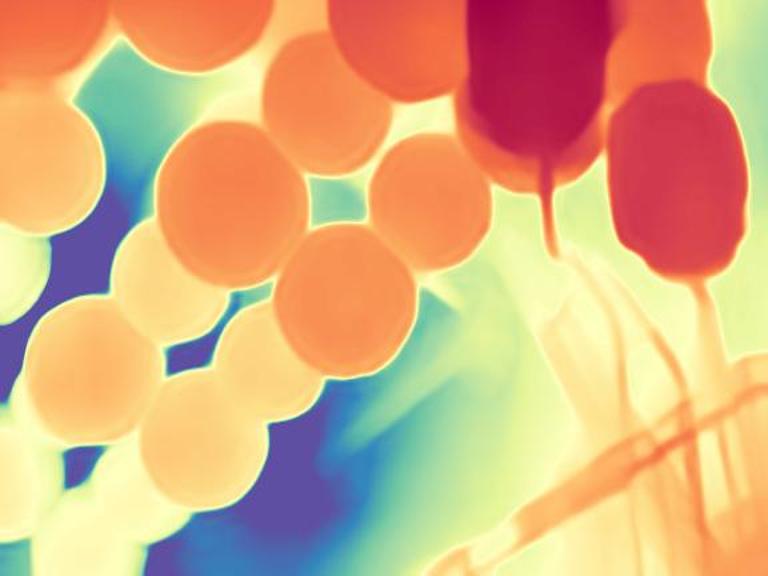
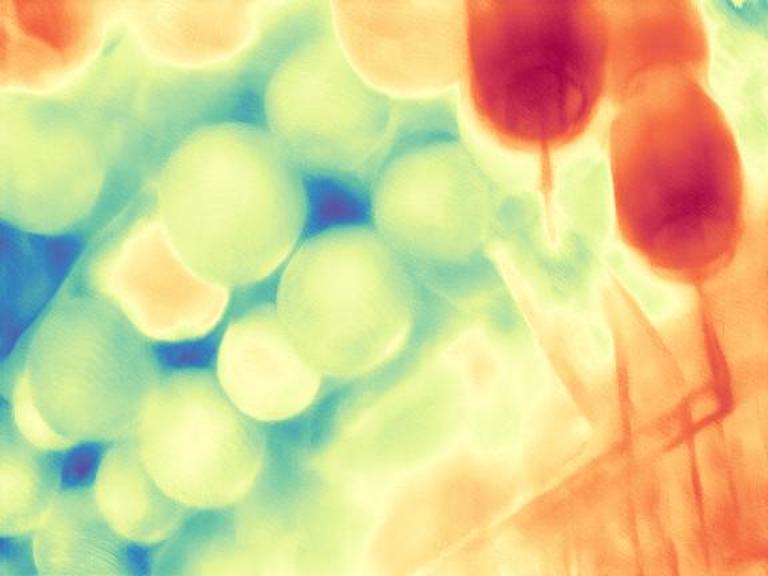
















































































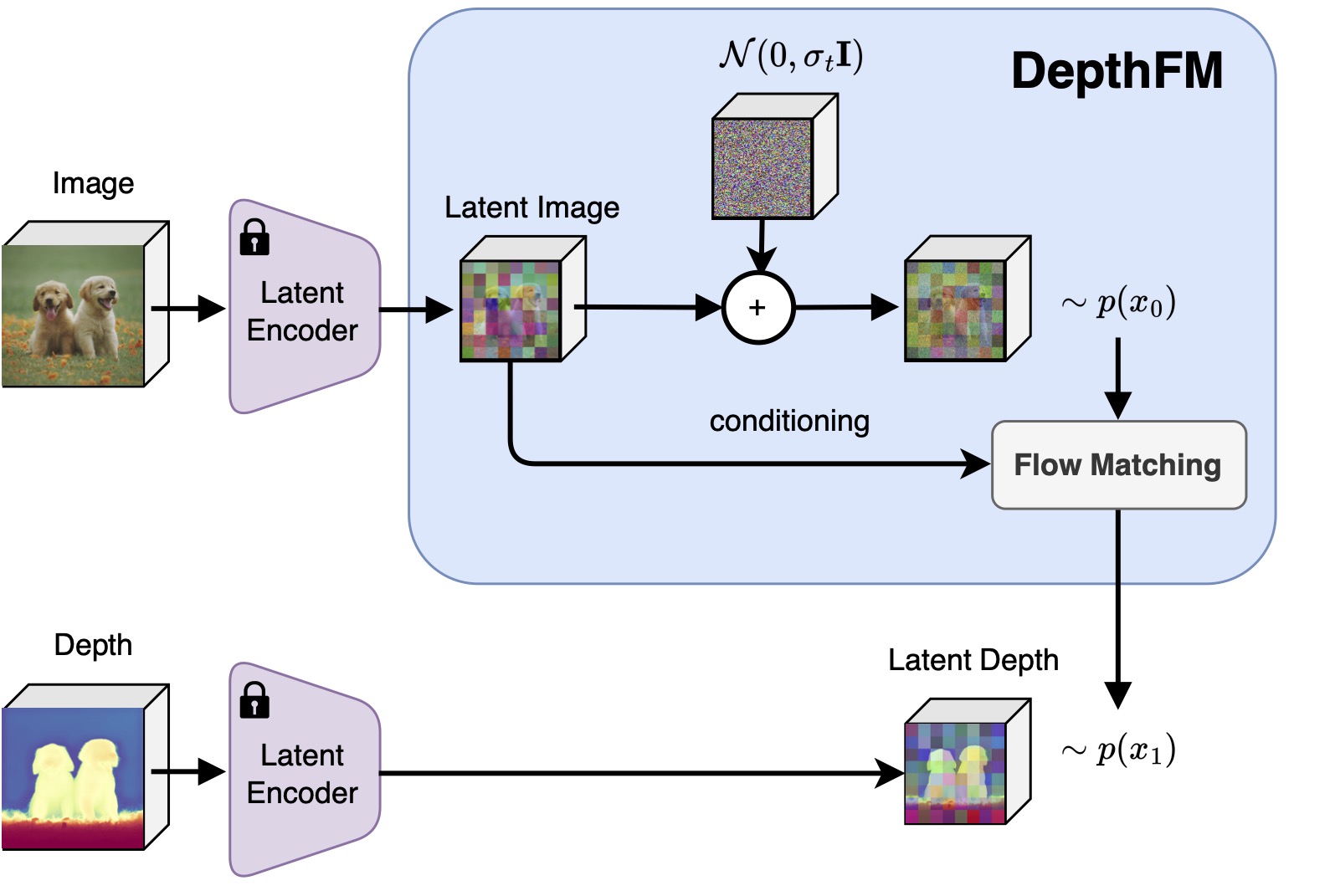
DepthFM regresses a straight vector field between image distribution $x$ and depth distribution $d$ by leveraging the image-to-depth pairs. This approach facilitates efficient few-step inference without sacrificing performance.
We demonstrate the successful transfer of the strong image prior from a foundation image synthesis diffusion model (Stable Diffusion v2-1) to a flow matching model with minimal reliance on training data and without the need for real-world images.
Generative depth estimation models offer high visual fidelity but often lag in quantitative metrics compared to discriminative models. Using a discriminative depth model as a teacher, we enhance our generative model by curating a broader dataset, improving robustness and performance while preserving depth fidelity.
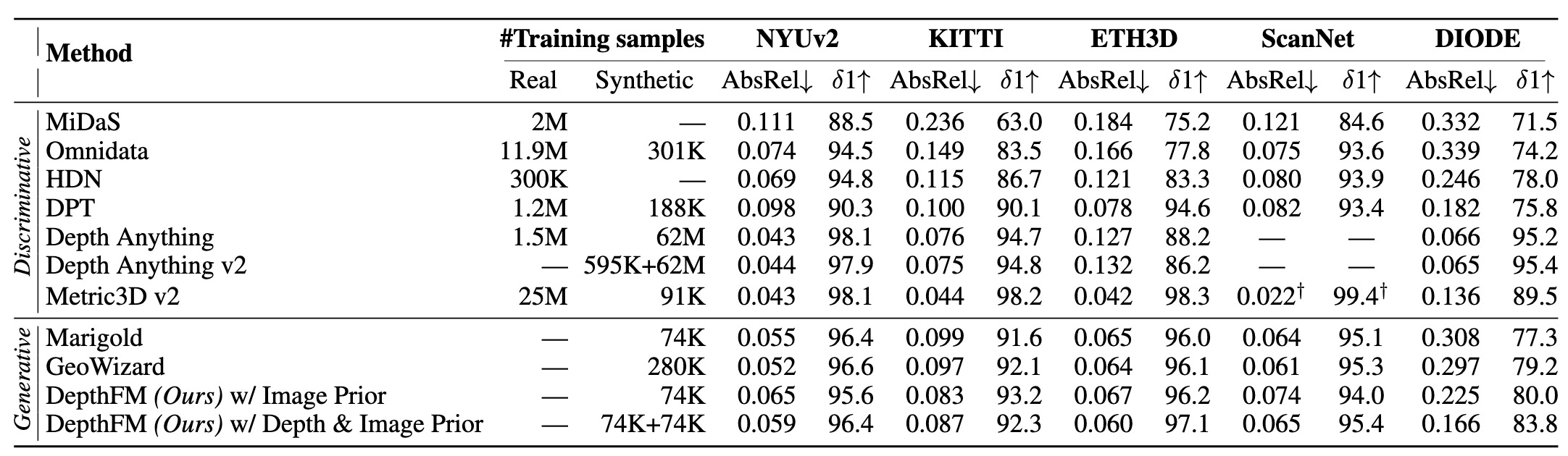
Quantitative comparison with affine-invariant depth estimators on zero-shot benchmarks. $\delta 1$ is presented in percentage. Our method outperforms other generative methods across the datasets in most cases. Some baselines are sourced from Marigold and GeoWizard. State-of-the-art discriminative models, which heavily rely on extensive amounts of training data, are listed in the upper part of the table for reference. $\dagger$: Results are trained also with normals.